
2017年我曾经基于Graphcore的CTO Simon Knowles的演讲两次分析了它们的AI芯片。最近,我们看到更多关于IPU的信息,包括来自第三方的详细分析和Graphcore的几个新的演讲。基于这些信息,我们可以进一步勾勒(推测)出IPU的架构设计的一些有趣细节。
我们先来回顾一下IPU硬件架构中的一些关键点。IPU采用的是大规模并行同构众核架构。其最基本的硬件处理单元是IPU-Core,它是一个SMT多线程处理器,可以同时跑6个线程,更接近多线程CPU,而非GPU的 SIMD/SIMT架构。IPU-Tiles由IPU-Core和本地的存储器(256KB SRAM)组成,共有1216个。因此,一颗IPU芯片大约有300MB的片上存储器,且无外部DRAM接口。连接IPU-Tiles的互联机制称作IPU-Exchange,可以实现无阻塞的all-to-all通信,共有大约8TB的带宽。最后,IPU-Links实现多芯片互联,PCIe实现和Host CPU的连接。
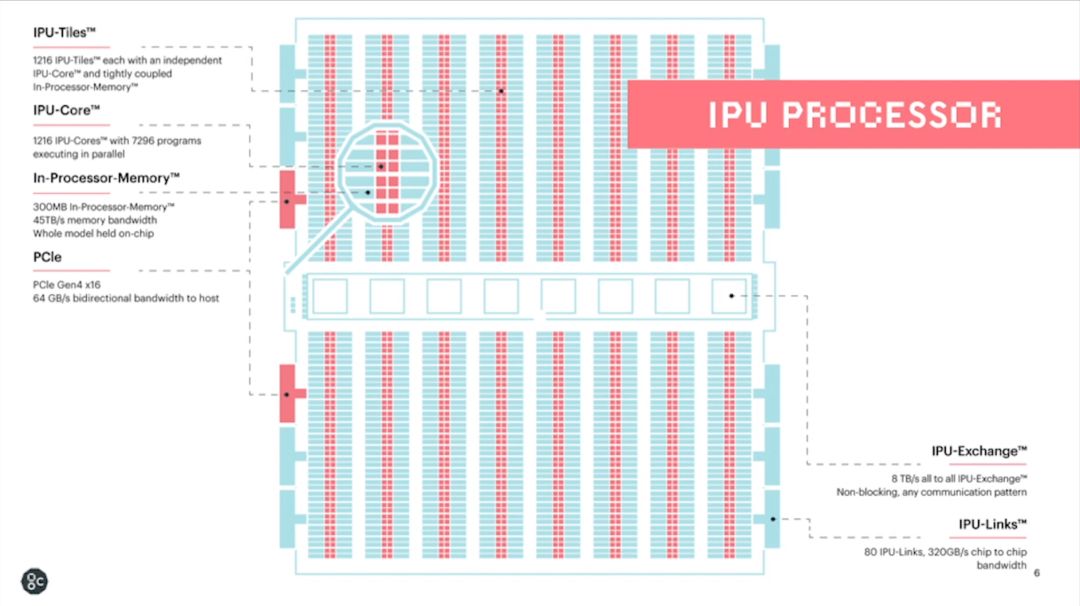
在我们做进一步讨论之前,大家不妨先思考一下这个架构的优势,劣势和实现的挑战。
对于一个同构众核架构来说,一般不追求单个核的性能。因此,单个核的设计是比较简单的,而芯片是通过把大量小核“复制”连接构成的。这种架构的整体性能(特别是throughput)主要体现在大量处理器核同时工作形成的大规模并行处理能力。而主要的挑战在于:1. 算法和数据本身是否有足够的并行性(Amdahl's law)2. 要充分发挥众核的效率,处理器核如何协同工作(通信,同步和数据一致性等问题)。
第一个问题的答案是肯定的。目前的AI芯片主要是用于加速神经网络计算的,其模型和数据都有很多并行性可以挖掘,这也是几乎各类AI芯片需求成立的基础。以前,类似的众核结构不是很成功,其主要原因也是没有合适的应用,有锤子没钉子。从这个角度来看,IPU并不是发明了锤子,而是找到了合适的钉子。即便如此,不同的模型和算子的并行性特征是有很大差异,比如CNN和RNN,稠密矩阵和稀疏矩阵,基本的Convolution和Grouped/Separable Convolutions。要用一个架构高效支持所有应用是不可能的,必须在设计中进行权衡。第一个架构设计的问题来了,Q1:采用什么样的基本操作粒度?
而第二个问题则涉及多核/众核架构的传统挑战,Q2:多核如何协同工作?
此外,尽量利用片上存储进行计算的优势是很明显的(可以参考我之前的文章,解密又一个xPU:Graphcore的IPU,Graphcore AI芯片:更多分析)。但是, 300MB的片上存储对控制机制和芯片实现都是巨大的挑战。下表是IPU和CPU,GPU的片上存储的一些对比,大家可以感受一下。
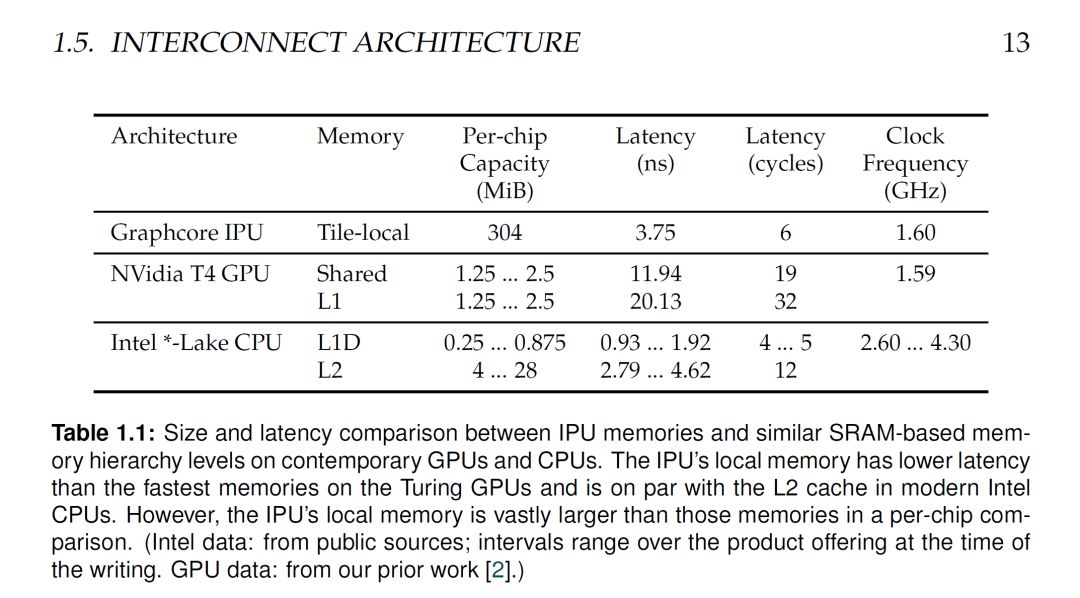
而这种设计还有一个很明显的问题就是,Q3:没有外部DRAM,如果模型放不下怎么办?特别是在模型越来越大的背景情况下,这个问题可能是大家关注最多的地方。
下面就从上述三个问题出发来讨论一下IPU的设计。当然,如我多次所说,架构设计就是trade off,IPU的设计只能说是权衡的结果,而不一定是最佳方案(其实也不一定存在最佳方案)。因此,对于我们来说,思考和讨论才是本文想达到的主要目的。
Q2:多核如何协同工作?
我想先讨论第二个问题,因为IPU对这个问题的回答,实际上决定了IPU的编程模型,同时也对架构设计和芯片实现有重大的影响。
IPU采用了一个称为BULK SYNCHRONOUS PARALLEL (BSP)的运行模式。这种模式把一次处理分成三步:
1. 本地计算(Computation):每个IPU-core进程都执行仅在本地内存上运行的计算。在此阶段,进程之间没有通信。前提是本地数据要准备好。
2. 同步(BSP Sync),在所有进程都达到同步点之前,任何进程都不会继续进行到下一个步骤。除了同步点本身以外,此阶段都不会进行计算或通信。
3. 通信(Exchange):进程交换数据, 每个进程可以向每个期望的目的存储器发送消息(单向)。在此阶段不进行任何计算。这里要指出的是,数据交换不是仅限于单个IPU,而是可以通过IPU-Link把数据发送给同一板卡或不同板卡上的其它IPU。
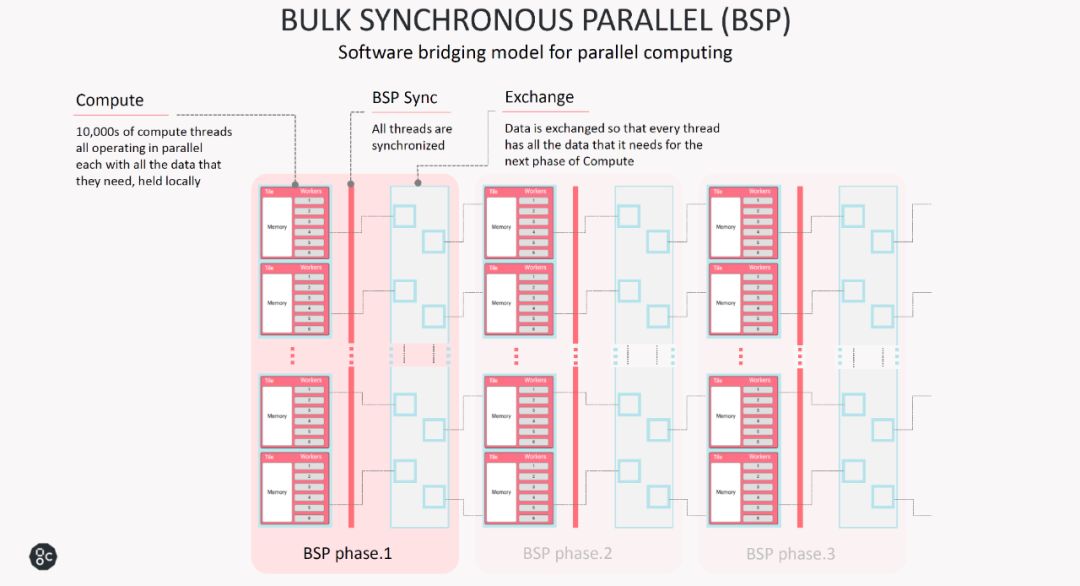
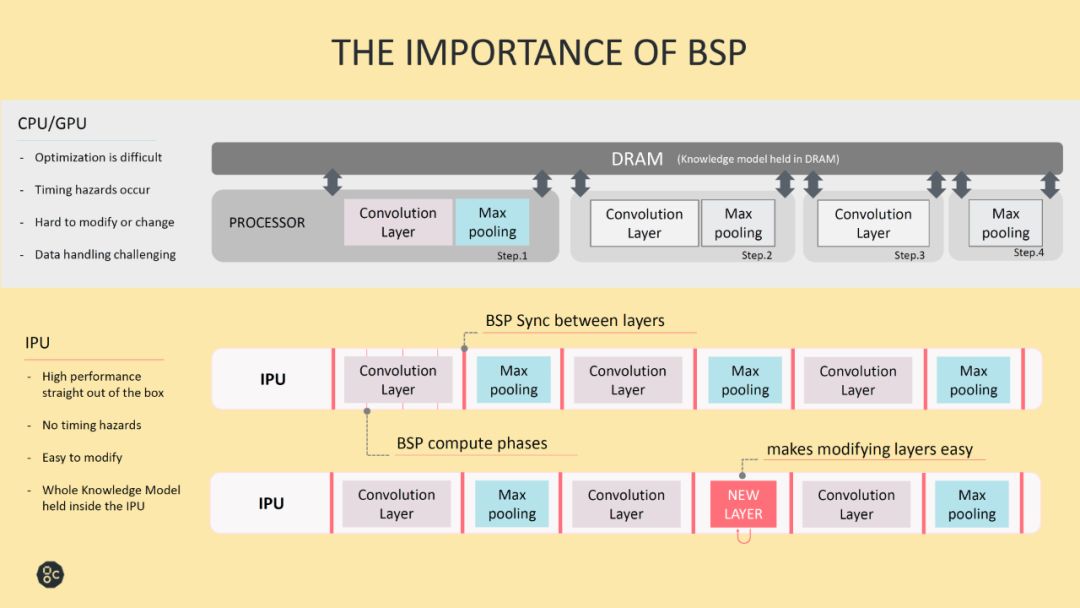
上图给出了BSP模式的优势,在我看来,这个模式最大的优势就是简单。首先,使用这个模式,众核设计中一系列头疼的问题要么大大简化,要么就基本不存在了。第一,通信是单向,只需要从源位置写到目的位置即可,且通信的同时是不进行运算的,芯片的所有能源都可以用作通信,有利于保证通信的性能。如果不是这种简化,很难想象IPU是如何实现8TB带宽all-to-all通信的。同步机制也很轻松,只需要支持发送简单消息即可,也没有时序上的风险了。数据一致性的问题不存在了。第二,这个机制中,处理器核只操作本地存储器,这样可以大大简化处理器核的访存设计。第三,片上存储在同一时间只有一个master在访问,控制逻辑也可以大大简化。这个应该也是IPU能够实现这么多的片上存储的原因之一。[1]中的实验配置里,IPU可以工作在1.6GHz。考虑到IPU使用的是16nm工艺,如果不是大幅简化了片上存储和通信机制,整体达到这个时钟频率是相当困难的。
那么,缺点呢?也很明显。第一,计算和通信必须是串行的。我们经常看到的AI系统优化里提到计算时间掩盖通信时间的策略,目的是支持计算和数据搬移并行执行,缩短整体消耗的时间。Graphcore对串行机制的解释是,在Dennard scaling难以为继的背景下,芯片工作的限制在于功耗,大芯片在实际工作时是不可能所有晶体管同时工作的(Dark Silicon问题)。因此,他们把计算和通信串行来做,两者都可以在功耗限制下发挥最高性能,整体时间来看并不比并行要差(详见我之前的文章)。遗憾的是,要严格的比较串行和并行模式的实际性能是非常困难的,所以这里我们也只能留下个疑问。第二,所有的处理器核(包括多芯片情况)都必须按照统一的同步点来工作,如果任务不平衡,就一定会出现处理器核空闲等待的情况。[2]中就给出了一个实际的例子,使用同一个板卡上的2个IPU实现BERT inference的情况。可以看出,开始由于无法平衡的分配任务,IPU0的利用率就比较低。
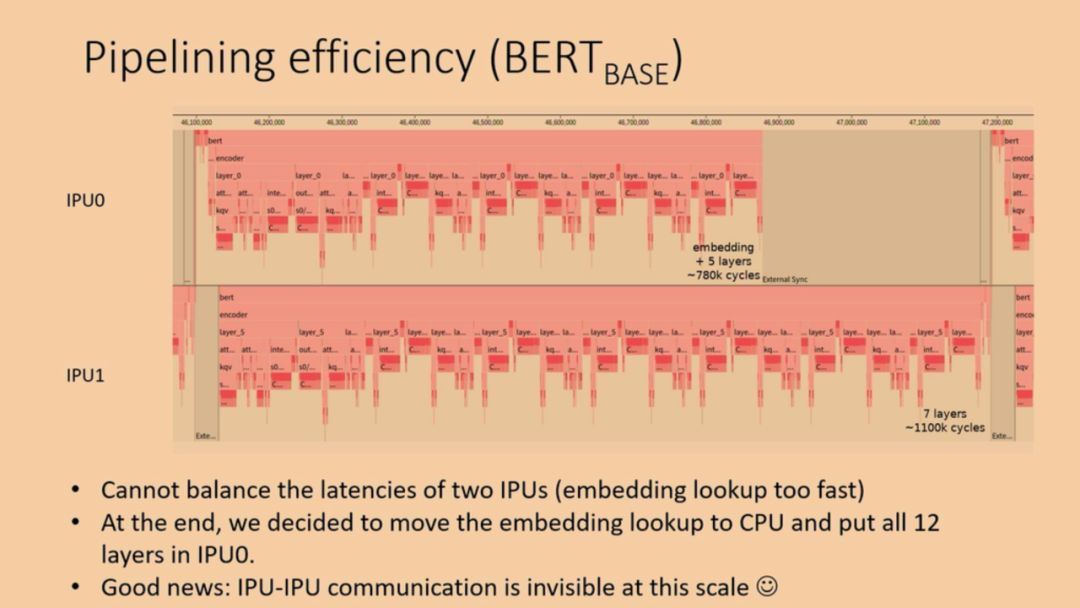
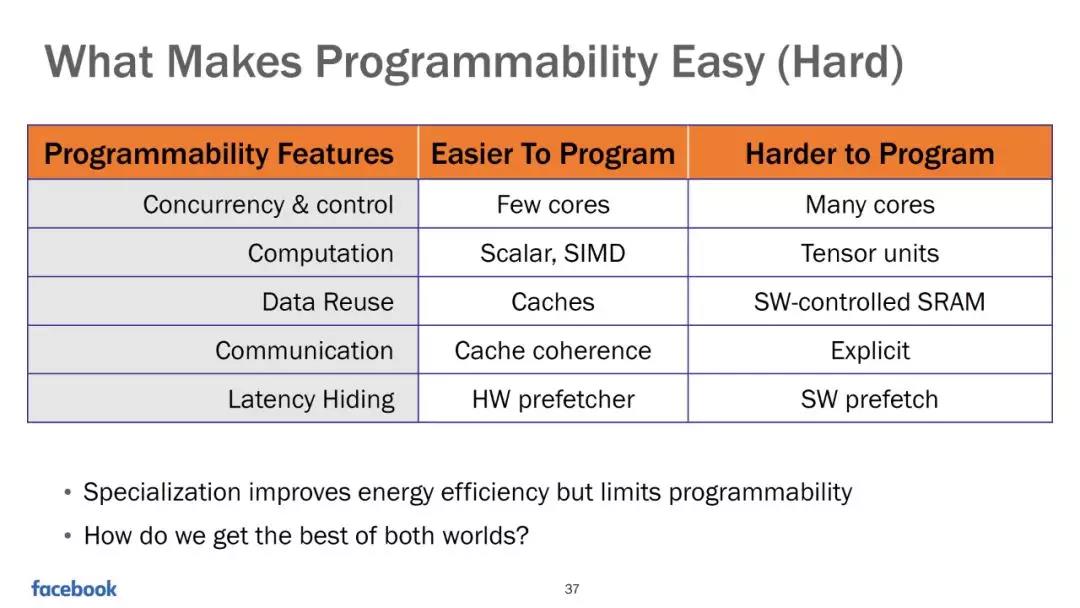
总得来说,BSP模式决定了IPU的硬件设计和编程方法,简化了硬件设计难度的同时,给软件工具带来了更多的挑战。这里插一张facebook的slides,大家可以参考一下。
回到主题,[1]中对IPU的片上和片间互联做了大量讨论和benchmark,具体数据也挺有意思,可以推测到一些实现细节,大家感兴趣的话不妨看看。不过,在理解的IPU的基本设计思路之后,各种测试结果也就很容易理解了。
Q1:“采用什么样的处理粒度?”
上述讨论中,我们可以看到,在设计多核协同工作模式的时候,IPU选择了一个粗粒度的模式。而在处理器核的设计中,IPU则选择了细粒度和更高的灵活性。从目前的资料来看,IPU-core是一个相对比较通用的处理器,支持6个线程,包括了一个Accumulating Matrix Product (AMP)单元,每周期可以实现64个混合精度或者16个单精度浮点数的操作。但是,IPU-core访问本地SRAM的端口并不宽,读写端口最大都是128 bit(据说有两读一写三个端口)。因此,IPU-core的处理粒度的比较细的,不是Nvidia GPU的TensorCore这个粒度的,更不是NVDLA的处理粒度。这也意味着在处理稠密矩阵运算的时候,IPU-core并不能最大限度的利用模型和数据的并行特征。[1]中所作的GEMM Benchmark也证实了这一点。单片IPU的混合精度处理能力是124.5T,和V100的TensorCore处理能力125T,是类似的。但实际IPU的GEMM运算效率只能达到50%左右,比TensorCore低不少。
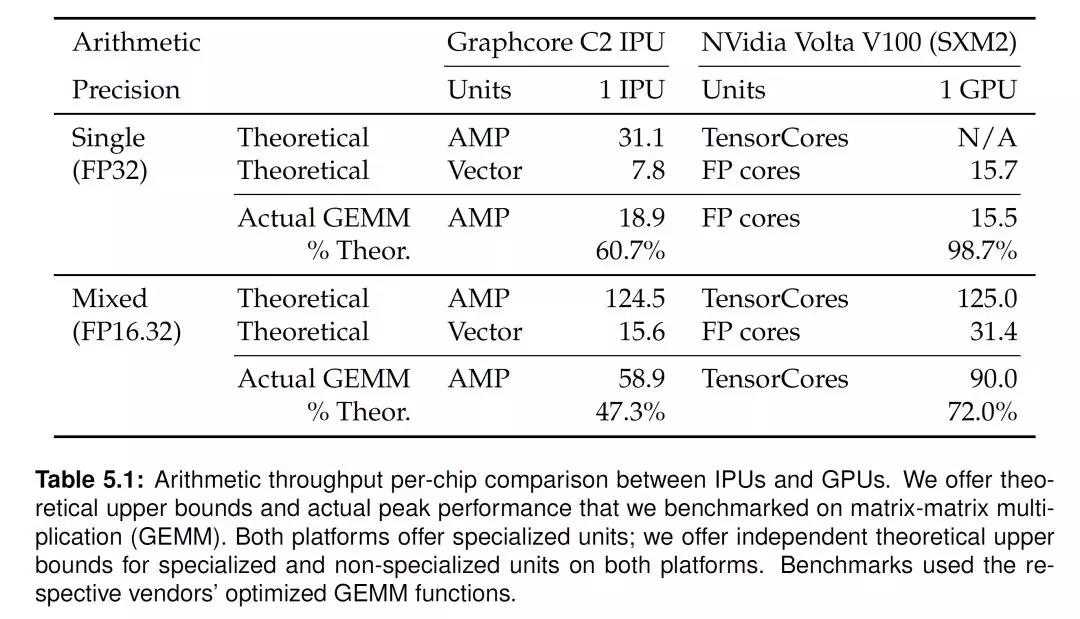
当然,这种设计的好处是处理器核有更好的通用性和灵活性。如果考虑稀疏模型,图网络,和一些特殊的Convolution运算,比如Grouped或者Separate Convolution的时候,这种细粒度的处理架构就会表现出相对优势。这也可以从[1]中的ResNeXt网络的Benchmark结果反应出来。
从最近Graphcore给出的Benchmark和宣传来看,他们在努力扩展IPU的应用场景,或者说寻找IPU架构能够发挥更大效率的应用和算法,比如金融领域。他们还提了个IPU thinking的概念,即在做算法的时候考虑充分利用IPU架构的特点。让大家从GPU thinking转换到IPU thinking可能是个很艰巨的任务。但与其和Nvidia正面竞争,试图取代GPU,可能还不如多培育更适合自己的应用(新的钉子),找到能够和CPU,GPU共存的空间。
Q3:“没有外部存储,如果模型放不下怎么办?”
从设计之初,IPU就是想兼顾data center的training和inference的。而和其它的data center芯片(特别是training芯片)相比,IPU最大的一个差别就是没有外部DRAM。在最近的NeurIPS 2019的一个讲演中,Graphcore的Tom Wilsonk分享了利用IPU做BERT training和inference的示例,正好可以帮助我们分析这个问题。
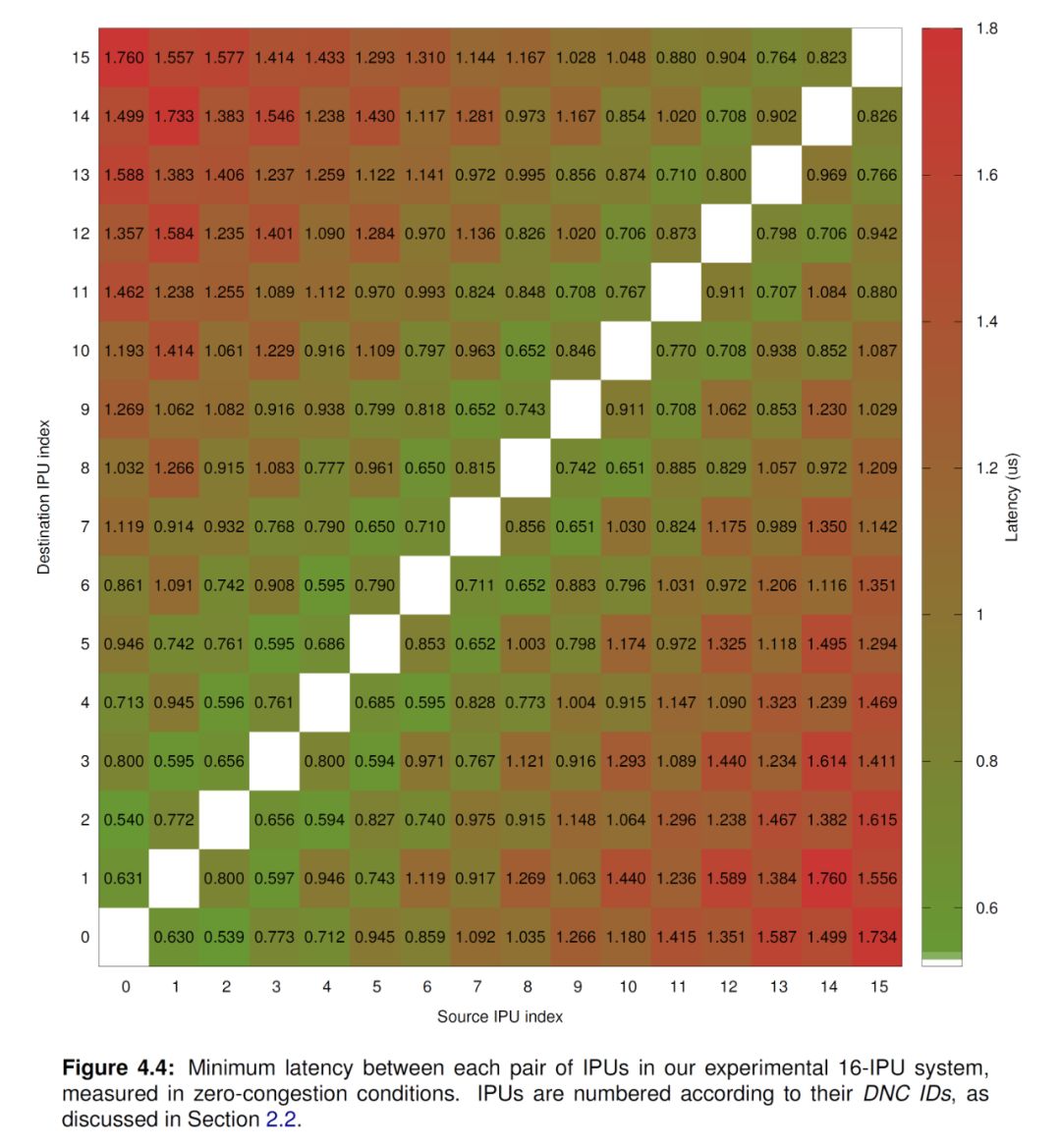
总得来说,Graphcore的解决方式包括了几个方面。第一,是多芯片互联。这个说起来很简单,一个芯片放不下就多来几个,但实现中对片间互联机制的要求很高。前面介绍了IPU可以通过IPU-Link进行多芯片扩展,从[1]中可以看出,多个IPU芯片可以构成一个大的虚拟IPU(如下图所示,最大8张卡16颗芯片)。虚拟IPU的编程模型和单个IPU是类似的,差别仅在于,数据交换阶段,数据要发送到最远的IPU需要更长的延时。更详细的延时数据,大家可以在[1]中查到。
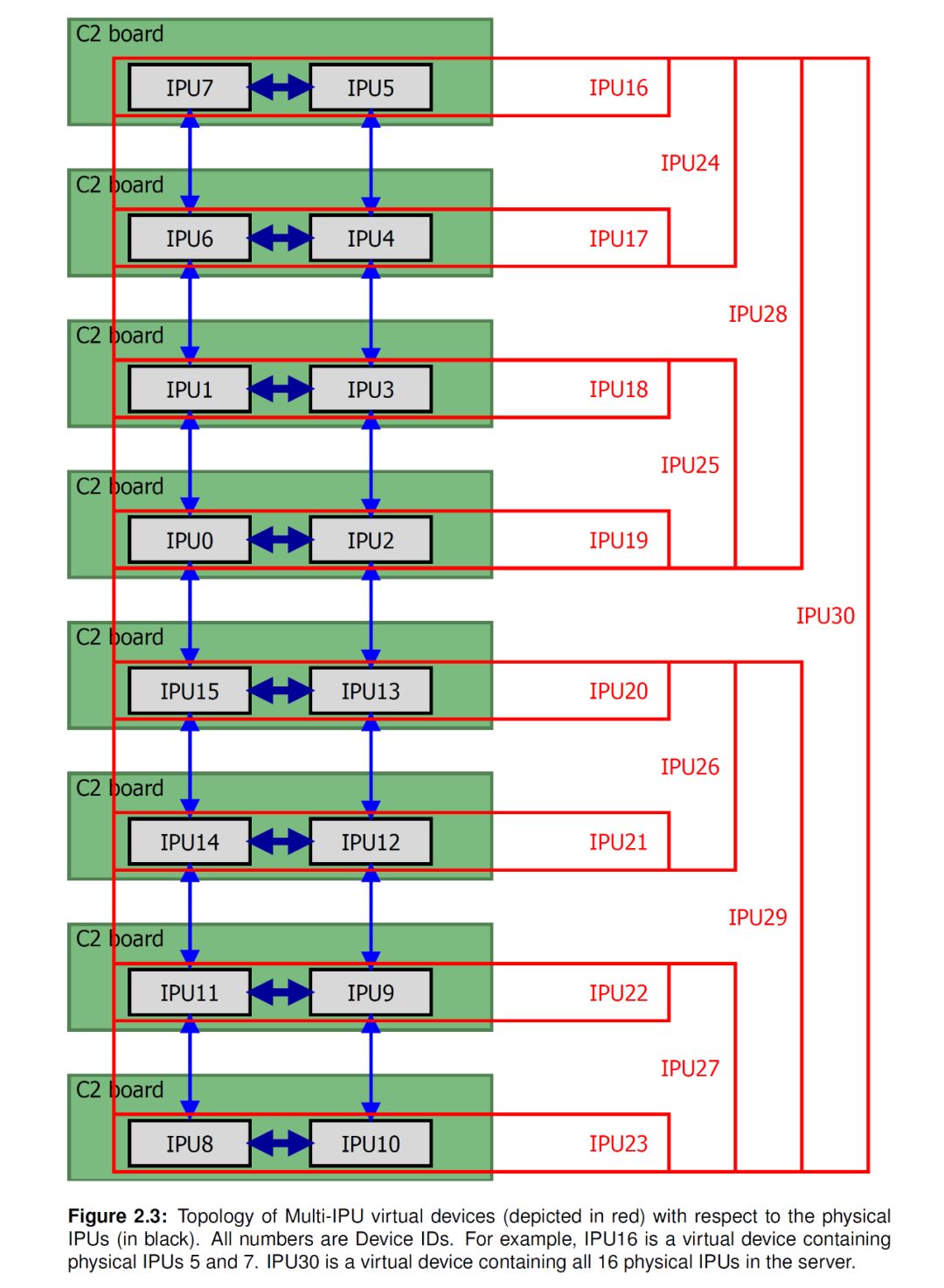
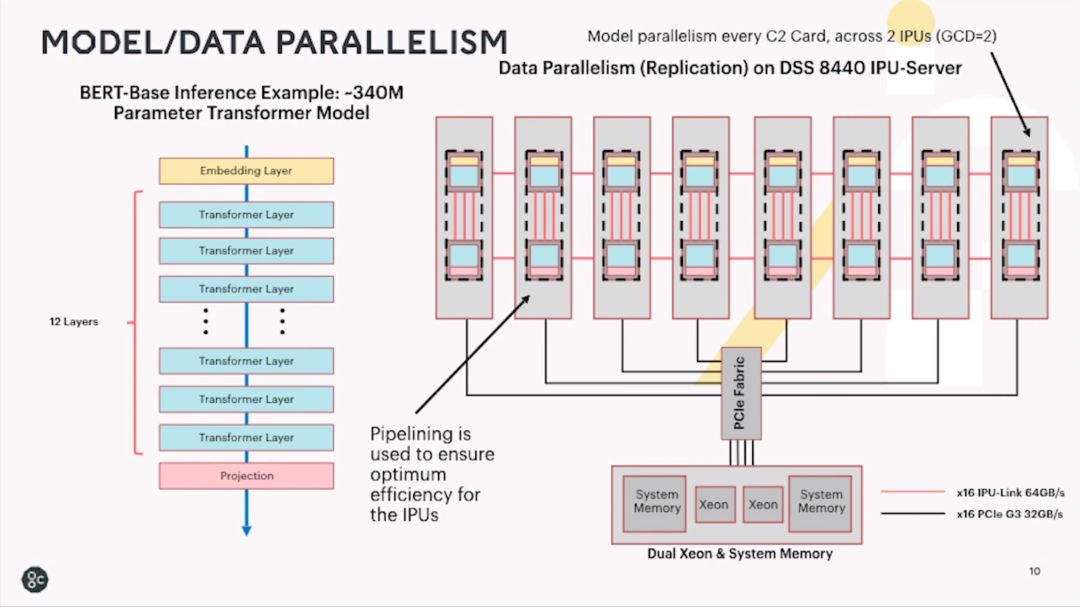
第二是模型并行,即把模型分布到多个核甚至多个芯片来执行inference或training。下面两个图分别是BERT模型的inference和training的配置。其中一路inference可以用两颗IPU芯片实现(和[2]分析的类似),training则使用7张卡,14颗IPU芯片采用pipeline的模式实现。
更近一步,一个有趣的问题是,Graphcore是否会在下一代产品中加上外部存储的接口呢?如果要加的话,基于BSP的编程模型是否需要修改?片上通信是否也需要做比较大的改动以匹配外部存储的数据带宽呢?片上的处理器核数量或者SRAM数量是否要减少呢?等等。感觉这个改动有可能会对IPU架构设计的基础产生很大影响,也许并不是单纯加个DDR/HBM接口这么简单。或者,可以不改变基本的架构设计理念,而是通过chiplet的模式直接在封装里扩展更多的IPU... ...
让我们拭目以待吧。
Reference:
[2] Ryota Tomioka, “Programming the Graphcore IPU”, MLSys: Workshop on Systems for ML 4, NeurIPS 2019, https://slideslive.com/38921983/mlsys-workshop-on-systems-for-ml-4
[3] Tom Wilson, “New approaches to NLP”, NeurIPS 2019, https://youtu.be/58QR5gCgEl8
[4] Victoria Rege, “OUR IPU LETS INNOVATORS CREATE THE NEXT BREAKTHROUGHS IN MACHINE INTELLIGENCE”, AI HARDWARE SUMMIT 2019, https://www.kisacoresearch.com/presentations/1463
题图来自网络,版权归原作者所有
凌美芯经授权转载
如需转载,请联系原作者
分享给朋友或朋友圈请随意


