本文为凌美芯团队联合上海交通大学进行的“基于 YOLO 深度神经网络的视频物体检测与识别 FGPA 加速项目”总结,我们将分3期为您展示整个项目,敬请关注并期待!
作者:
Leech、董浩、江子山 上海交通大学计算机科学与工程系
刘剑、邓秋平 凌美芯(北京)科技有限责任公司
Yolo 是一个基于卷积神经网络的图像检测与识别算法, 能够检测并识别出图片中的特定物体并将标注出来。Yolo 可以集成到各种设备中, 进行视频流的物体检测与识别。本项目中将 Yolo 移植到 Xilinx FPGA 平台, 使用 FPGA 的逻辑和 DSP 资源对其进行加速, 使其处理速度能够达到 25fps, 从而能够对实时视频进行实时处理。
FPGA 平台的输入是图片, 输出是对图片中检测出物体进行标注, 包括矩形框和类别标签。下面是 Yolo对一张图片进行处理的结果截图。本项目产出两个 Yolo FPGA 加速器设计, 并经过测试。加速器可以以多种方式集成到应用系统中, 如从摄像头或者 SD 卡中读入视频, 在显示屏中显示标注。
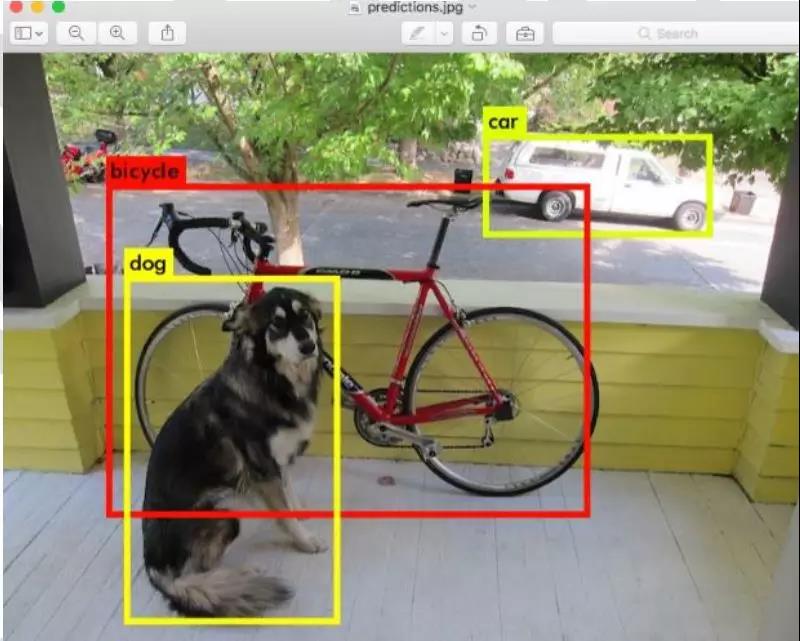
YOLO算法介绍
Yolo 共分为三个版本, 最小的是 yolo-tiny, 我们本次实现的就是 yolo-tiny, 其主要的网络拓扑结构及参数配置如下:
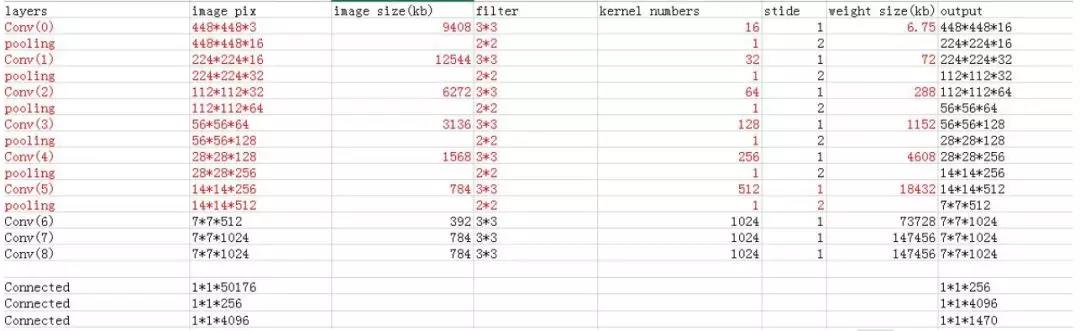
Yolo 卷积神经网络主要分为卷积层和全连接层。 项目组根据其计算需求特征进一步分为三个部分: 红色卷积层, 黑色卷积层以及全连接层。 红色卷积层共分为 6 个卷积+池化层,黑色部分由 3 个卷积层组成, 最后是 3 个全连接层。 这三个部分的计算方式是不一样的, 至于红色卷积和黑色卷积在硬件上实现的计算方式, 请参考下文红色卷积和黑色卷积计算方式的详细说明。 而对于全连接层, 其计算方式与卷积层有着很大区别, 这个在这里就不具体阐述。
基于 Verilog 的设计方案
在项目的试水阶段, 课题组使用 Verilog 实现了 yolo-tiny 设计, 其处理速度最高 10fps,下面介绍一下我们的设计方案。
红色卷积和黑色卷积计算方式说明
我将卷积层分为两部分, 前面一部分我用红色标记, 后面用黑色标记。 红色卷积部分是
典型的“pixel 大、 weight 小”类型, 而黑色卷积部分属于典型的“pixel 小、 weight 大”类型。前面一部分适合“pixel load once”, 后面一部分适合“weight load once”。

所以其实针对不同的类型, 应该采取不同的计算方式。 我们目前的架构采取的“pixel loadonce”方式, 在计算黑色卷积部分时, 重复 load weight 导致带宽急速增大。 所以, 在黑色卷积部分, 我们应该采取“weight load once”的计算方式。“weight load once”和“pixel load once”一样, 也是采取 kernel 内并行的方式, 其区别就在于:“pixel load once”是每次取一部分数据,给 kernel 轮流算, 当全部 kernel 都计算完这部分数据后, 取下一部分的数据,然后再 load 全部 kernel 对这部分数据进行计算;而“weight load once”是一个 kernel 对所有的 pixel 都计算完之后, 再 load 下一个 kernel 对所有的 pixel 进行计算。 在这种方式中, 一个 kernel 在计算完一部分数据后, 不换 kernel, 而换 pixel; 同一个 kernel 对新的 pixel 进行计算。 当一个 kernel计算完毕后, 产生一个完整的 output feature map。 可见, 这两种计算方式产生结果的顺序是完全不一样的。“weight load once”产生结果的顺序如下图所示:

产生一个 output feature map 后, 用同样的计算方式产生下一个 output feature map。需要注意的是:这种计算方式读取和写入 pixel 顺序是一样的。这导致了一个问题:红色卷积最后一层产生 pixel 的顺序和黑色卷积第一层读取 pixel 的顺序是不一样的。这部分数据是14*14*256*2/1024 = 98KB 大小。一种可能的解决方案为采取速率较慢的 memory-mapped 方式写入到 DDR 中, 而除此之外的所有其他的内存写方式都是 burst write。同时, 黑色卷积每一层中的 input feature map 都很小, 其中最大的才 784Kb(44 个 18Kb BRAM 即可装下),所以 pixel 也只是需要从内存装载一次, 重复读取的带宽都是在 BRAM 和 PE 之间的内部带宽, 我们暂时不考虑。这样, 卷积部分处理一帧图像的带宽使用情况如下表所示:

Weight 由之前的 376.5MB 降为 49MB, 通过优化极大的减少了访问内存所带来的性能损失。 下面在补充说明一下两种计算方式的区别:
1. “pixel load once”
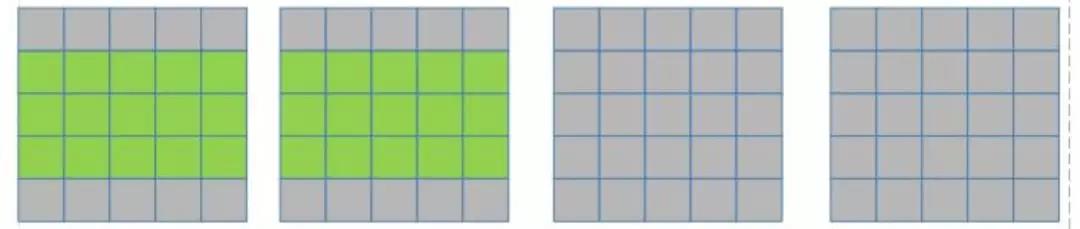
假设目前只有 2 个 PE, input feature map 也只有 4 个(如下图所示):
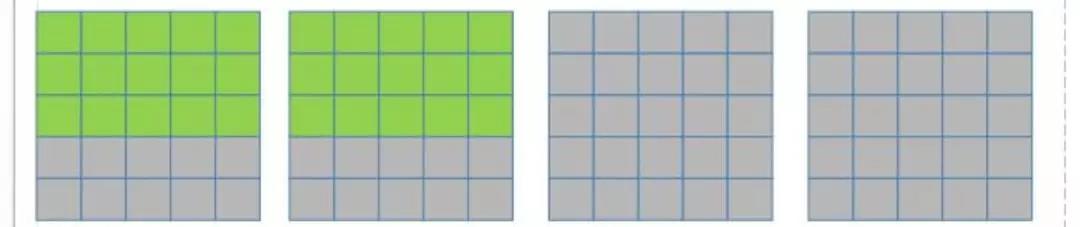
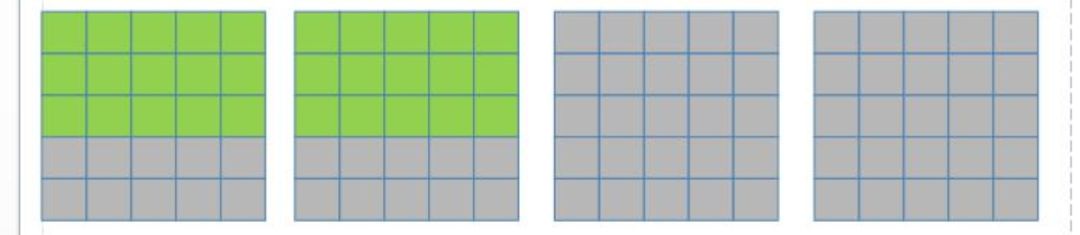
在一个 kernel 计算完两个 input feature map 后(3*3 卷积核的滑动窗口向右滑动, 覆盖上图绿色部分的像素点), 下一步该 kernel 再计算后面两个 input feature map(如下图所示):
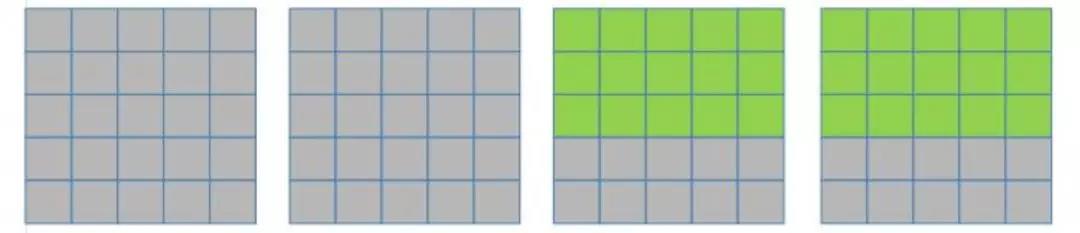
然后将结果相加, 得到一行输出。
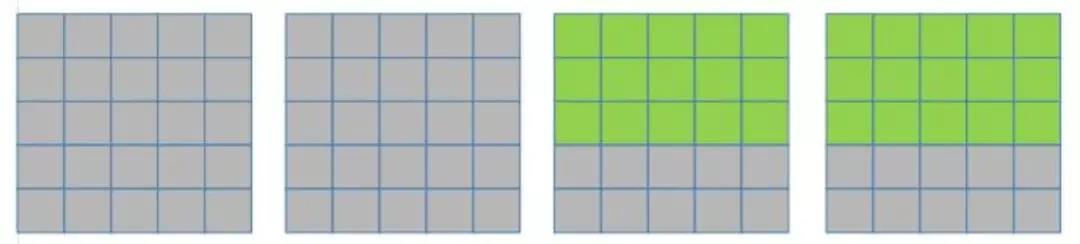
然后就是换一个 kernel 再计算相同的 pixel 数据, 也得出一行数据。直到所有的 kernel都对这些绿色的数据都计算完后, pixel 数据才会变, 变成下面这样:
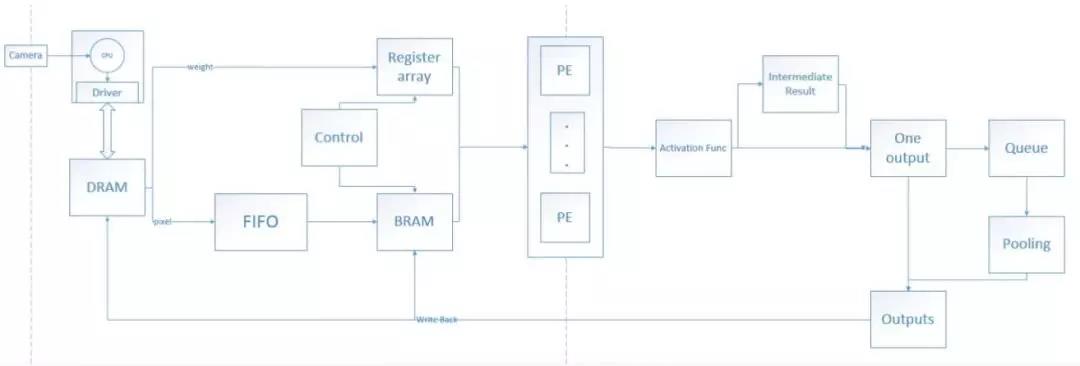
首先, 通过 DDR 驱动, 将所有的 weight 写入到 FPGA 的外部 RAM--DRAM 的相应位置。
接着, Camera 采集图像数据, 传递到 CPU;CPU 对其进行预处理, 包括抽取出单独的一帧图像并将多余的控制信息抽去, 只留下纯 pixel 数据, resize 成 448*448*3; 然后将这些 0~255的 pixel 数据映射成-1~1 之间的定点数, 至此, CPU 对于一帧图像的预处理部分完成。
最后,通过 DDR 驱动, 将一帧图像传递到 DRAM 的特定位置。
DRAM 传输到 FPAG 内部有三根线, 分别是 weight 数据线, pixel 数据线和控制信号线。通过 weight 数据线, 将需要的 weight 传输到一个寄存器组中, 该寄存器组保存的 weight 就是所有 PE(目前 64 个)下一次需要的 weight。 在卷积层, 一次传输的 weight 可以够 PE 使用多个 clock, 时间足够将下次需要的 weight 全部加载到寄存器组中; 而在全连接层, 则对于weight 的速度要求就比较高, 因为全连接层每个 weight 对应一个 pixel。Pixel 数据线只需要按序传输已经写入的 pixel 即可, 采取 stream 的方式进行 burst read, 我们写入到 DRAM 的结果的顺序已经是经过设计的, 读取只需要按序读取即可。Pixel 数据线将传输的数据先写入到 FIFO 结构中, 然后经过总控模块的控制, 将其写入到 BRAM 块中( 具体细节后面详细说明)。 然后, 依旧在总控模块控制下, pixel 和 weight 被 load 进 PE 中, PE 进行计算。
目前设计有 64 个 PE, PE 的并行方式是 kernel 内并行, 每个 PE 都属于同一个 kernel, 只不过其 filter 是对应不同 input feature map 的 filter, 所以, PE 每计算完一个结果, 都需要将所有 PE 的结果相加起来。 如果相加后得到的是一个最终结果了(如果 input feature map 比较多, 一次计算出的结果可能还只是一个中间结果, 此时需要将其暂存起来, 然后与后面的中间结果进行累加, 直到算出最终结果), 再对其进行激活函数(Leaky RELU), 如果其后面还有 Pooling 操作, 则将该结果加入一个暂时的 Queue 中, 积攒到 2*2 的相应位置的结果后进行 Pooling, 然后将最终结果写入到 DRAM 中。 可以看得出, 目前的计算架构每次只产生一个结果, 不会出现同一个 clock 产生多个结果的现象。
1. 红色卷积部分由于 pixel 较大, 每次产生的结果需要写会到 DRAM 中, 而黑色卷积部分和全连接部分则由于 pixel 较小, 所以计算结果直接保存到 BRAM 中, 无需与DRAM 进行交互。 在计算黑色卷积和全连接部分的时候, CPU 通过驱动将下一帧图像传输到 DRAM 中。
2. 最后一层全连接完毕后, 结果通过 AXI 线传输到 DRAM 中, 然后通过驱动传输到CPU 中, CPU 执行 YOLO 的 detection layer 操作, 计算出最终输出结果。 至此, 一帧图像处理完毕。
未完待续……
更多项目内容
敬请期待下期

LYNMAX凌美芯
微信号:LYNMAXTECH

