本文为凌美芯团队联合上海交通大学进行的“基于 YOLO 深度神经网络的视频物体检测与识别 FPGA 加速项目”总结,我们将分3期为您展示整个项目,本期为第2期,敬请关注并期待!

作者:
Leech、董浩、江子山
上海交通大学计算机科学与工程系
刘剑、邓秋平
凌美芯(北京)科技有限责任公司
1. 总控模块的实现方式
总控模块作为 YOLO 中的核心模块, 几乎控制了所有其他模块。其基本功能可以用如下
伪代码表示:
IF layer 属于红色卷积 THEN
按照红色卷积计算方式进行 pixel 的读写
给出 weight 的控制信号
layer += 1
ELSE IF layer 属于黑色卷积 THEN
按照黑色卷积计算方式进行 pixel 的读写
给出 weight 的控制信号
layer += 1
ELSE 全连接层
按照全连接层计算方式进行计算
layer += 1
总控模块根据 layer 所在的部分, 采取对应的计算方式和数据流方式。在红色卷积部分,
pixel 数据的写入发生在从 FIFO 中读取输入原始数据, 然后计算出 BRAM 块地址, 一次写入一个数据。而黑色卷积和全连接部分, 写入发生在 PE(activation 后) 计算出一个最终结果时, 此时不是将该结果写入到 DRAM, 而是写入到 BRAM 的特定地址中, 后面 pixel 数据全都是在 BRAM 中流通, 没有经过 DRAM, 减少了带宽。
下面我详细描述一下不同层次的计算方式。
(1) 红色卷积部分
红色卷积部分的特点是“weight 小, pixel 大”, 所以采取的原则是“pixel load once, weightload multiple times”。同时考虑到能够让 AXI 充分利用 stream 方式进行 burst read, 所以这部分读取数据的顺序和产生数据的顺序是完全一样的。Pixel 数据的组织形式如下:
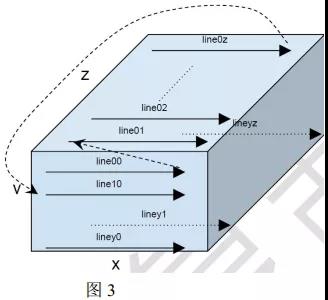
x-y 平面就是一个 input feature map, depth 为 z 说明有 z 个 input feature map。 但是我们存储数据的顺序是沿着 z 轴进行的, 以上图为例, 保存在 DRAM 中的顺序是 line00 line01line02 … line0z line10 … line1z … liney0 … lineyz, 每个 line 的长度就是 x, 如下图所示。 在将 pixel 传输到 BRAM 中后, 数据又是怎么存储的呢?
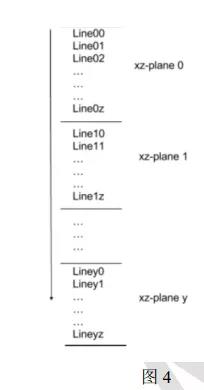
我们目前使用的 BRAM 块是 18-Kb 的 BRAM 块, 总共使用 64*3 = 192 块, 每 64 块 BRAM形成一个 z 平面, 所以共有 3 个 z 平面。 下面以一个 z 平面来解释其是如何组织数据存储的。
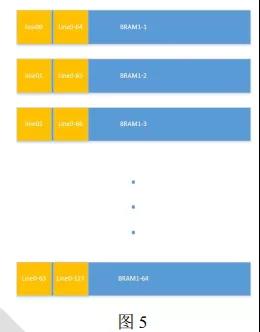
上图中, 总共有 64 个 BRAM 块, 形成一个 BRAM 池, 对应于图 3 中的一个 z 平面。 我们取第一个 z 平面( line00 ~ line0z) 为例。 每个 BRAM 块存取一个 line, 如果存完 64 个 line之后, 依旧没有存完图 3 中的一个 z 平面( 即 z>64), 那么继续顺序地从每一个 BRAM 块的后继位置保存后面的 line, 直至将图 3 中的第一个 z 平面全部 line 保存下来。 然后再按照相同的方法, 在第二、 第三个 BRAM 池中保存后面连续的两个 z 平面。 当三个 BRAM 池装满了三个 z 平面, 此时就可以读取数据进行计算了。
每个 BRAM 池中相同位置的 BRAM 块对应同一个 PE, 例如三个 BRAM 池中的第一个BRAM 块就对应第一个 PE。 每个 PE 在每个周期从其对应的三个 BRAM 块中读取数据, 每个 BRAM 块中读取一个 pixel, 所以每个 PE 一个周期读取三个 pixel。 依旧以第一个 PE 为例, 其第一个周期读取的 pixel 分别来自于 line00,line10 和 line20 的相同位置, 它们都是出于同一个 input feature map, 并且正好是同一列的连续三个 pixel。 在一开始, 三个周期后读取的 9 个 pixel 正好形成一个 3*3 的卷积区域, 后面每次进来新的 3 个 pixel, 就形成新的 3*3的卷积区域, 也就是每个周期都可以进行卷积操作, 产生一个结果。 其实, 看到这里也可以意识到, 每个 PE 其实输入只有一个 input feature map, 只是因为我们采取的是 kernel 内并行的方式, 每个 PE 上的 weight 其实就是一个 kernel 内对应于某一个 input feature map 的一个filter。
当第一个 kernel 算完这前三个 z 平面的数据后, 会产生 line01(这里没考虑池化), 然后换下一个 kernel 继续从 pixel 的一开始进行计算, 算完与前面 kernel 计算的相同的 pixel 数据后, 产生 line02, 直到最后一个 kernel 算完这些 pixel, 产生 line0z’(z’等于 kernel 个数),然后将这些 line 顺序传输保存到 DRAM 中, 是不是和上面介绍的 pixel 在 DRAM 中的存储方式一样? !
红色卷积部分的计算特点就是, 对于每份 pixel 计算单元(三个 z 平面), 都经过所有 kernel的计算之后才换新的 pixel 计算单元。 这也就是“pixel load once, kernel load multiple times”的含义。
当然, 上面说的三个 BRAM 池是不够的, 我们将每个 BRAM 池一分为二, 即每个 BRAM块的前半部分属于一个 BRAM 池, 后半部分属于另一个 BRAM 池, 从而达到 ping-pong 的效果。 因为计算完 1、 2、 3 的 z 平面后, 下一步要计算的 z 平面就是 2,3,4, 所以只需要向下推动一个单位就行, 对应 BRAM 池也是一样。
而在红色卷积部分, 每个卷积后面都有池化层, 所以每次 PE 得计算出 1 个 output z 平面后, 缓存在一个 Queue 区域(有 z’个 line), 然后每计算出一个 line 之后, 就和缓存的对应的 line 进行池化操作, 然后产生最终结果, 写入到 DRAM。 当第二个 output z 平面计算出来后, 就全部都和缓存的那个 output z 平面进行了池化操作, 最终两个 z 平面产生一个 z 平面的结果。
当然, 这里面还有 padding 的操作。 我们这里直接在存储的时候就做了 padding 的工作,保存在 DRAM 中的数据全部都是 pixel 数据, 但是在 BRMA 中, 我们不仅保存了 pixel 数据,还自动保存了 padding 数据
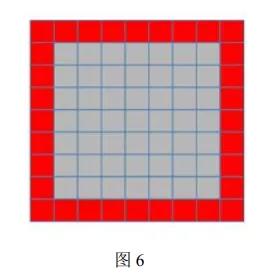
就像图 6 所示, 中间灰色的是 pixel 数据, 但是在 PE 看来的 BRAM 块中, 数据是包括padding 的, 这样就省得 PE 再去做额外的 padding 了。
(2) 黑色卷积部分
黑色卷积部分的特点就是“weight 大, pixel 小”, 所以采取的方式是“weight load once, pixelload multiple times”, 事实上, 由于 pixel 很小, 所以 pixel 其实就 load 1 次, 在 load 之后就直接保存在 BRAM 中了。
黑色卷积的 pixel 组织形式是 one-feature map-following-one-feature map, 也就是我们最好理解的一种方式。 计算的时候, 还是采取 kernel 内并行的方式, 但是和红色卷积的 kernel内并行方式有一点不同, 黑色卷积是计算完一个 kernel 后再换下一个 kernel, 所以当一个kernel 计算完毕后, 后面就再也不会再 load 它了。 每个 kernel 在计算完后, 都会产生一个output feature map, 所以最终产生的结果就是 one-feature map-following-one-feature map 的形式, 和读取的顺序是一样的。
但是, 这种方式在用 BRAM 池保存的时候, 为了充分利用 64 个 PE 的并行性, 需要的
控制难度就比红色卷积部分的高。 下面我详细描述一下如何用 BRAM 池来保存这样的 pixel。( 注意, 黑色卷积部分的 input feature map 的大小都是 7*7, 加上 padding 正好是 9*9, 这个9*9 对于我们的结构 alignment 很重要)。 注意: 一个 PE 有一个 filter, 其处理对应的那个 inputfeature map!
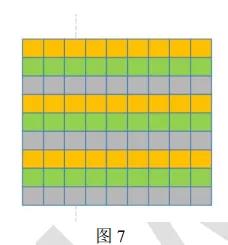
图 7 是一个 input feature map, 相同颜色的行保存在同一个 BRAM 块中, 而不同颜色的行保存在不同 BRAM 池中相同位置的 BRAM 块中, 其存储结构大致如下( 假设这个是第一个 PE 对应的 input feature map):
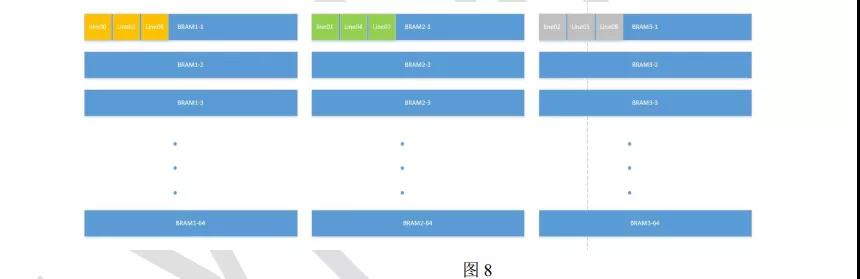
还是以第一个 PE 为例( 其他 PE 原理一模一样)。 在计算 input feature map 的前三行的时候, 直接从三个 BRAM 池中读取相同位置的 pixel 就行了, 很简单。 但是当前三行计算完毕, 计算 line01,line02 和 line03 的时候, 顺序变了! 变得复杂了!第一行和第二行数据分别是从第二个 BRAM 池和第三个 BRAM 池的相同位置取出, 而第三行的数据则是从第一个BRAM 池的不同位置取出, 这个只要控制逻辑控制得当, 是完全可以做到的, 因为每个BRAM 块的读写都是独立的, 地址可以不同。还有一个问题就是数据的 rearrange, 需要加一个模块, 将从三个 BRAM 池中取出的数据按照正确的顺序传递给 PE。
上面的三个 BRAM 池相同位置的三个 BRAM 块保存了一个 input feature map,三个BRAM 池后面的相同位置的每三个 BRAM 块都保存一个 input feature map, 这样就保存了64 个 input feature map, 剩余的 input feature map 则继续在每个 BRAM 块后继位置继续填写,完全按照一样的模式, 直到将 512( 1024) 个 input feature map 都填满, 1024 个 input featuremap, 平摊到每个 BRAM 块的大小是 6.75Kb, 每个 BRAM 块的大小是 18Kb/2 = 9Kb(因为我们将每个 BRAM 块一分为 2 了), 完全够! 这样, 64 个 PE 计算出 9*9 的中间结果, 每次将计算出的中间结果想加, 直至将 512( 1024) 个 input feature map 都计算完, 产生一个最终的 output feature map, 写入到另一半的三个 BRAM 块中。 此时, 换下一个 kernel 再对 inputfeature map 进行计算。 所以, 产生结果的顺序就是 one-feature map-following-one-feature map,写入到 BRAM 的时候也很好写, 这里就不深入展开了。
(3) 全连接部分
全连接部分, 由于每个 weight 和每个 pixel 都是一一对应的, 所以每个都是“load once”,没有复用。这里, pixel 在 BRAM 中的保存形式是:
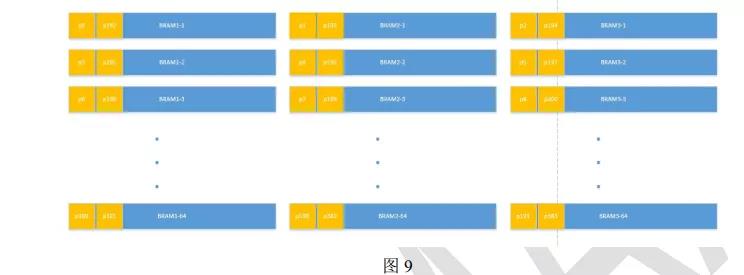
这里每个黄色小框代表一个 pixel(注意和上面图 8 代表的含义不一样), 全连接层写入
pixel 的顺序是每个 BRAM 块写一个 pixel, 然后跳转到另一个 BRAM 池的一个 BRAM 块中写下一个 pixel, 顺序可以从上图看的很清楚。 这样, 每个 PE 一个周期取出 3 个 pixel, 由于数据不能复用, 所以全连接阶段, PE 的利用率只有 1/3, 因为一个 clock 只能计算 3 个 pixel,而不能像卷积层那样, 一个clock计算9个pixel。但是, 全连接的operations只占所有operations的 1%左右, 这部分利用率不高目前也不是大问题, 优化问题将在后面的版本中进行, 本版本目前就采取这种计算方式。 注意, 第一层全连接层的输入是黑色卷积部分最后一层产生的结果, 在写入结果时, 得按照全连接的顺序进行写入。 全连接计算完毕, 将结果写回到 DRAM中, 然后传输到 CPU 中做最后的处理。
2. weight 的传输与读取
weight 的控制相对简单, 每次只取 64 个 PE 一次计算所需要的 weight, 全部保存在寄存器组中, 然后当 PE 当前的 filter 计算完毕, 就会将新的 weight 加载进去, 此时再通知控制器, 从 DRAM 取下一批需要的 weight, 再保存到寄存器组中。
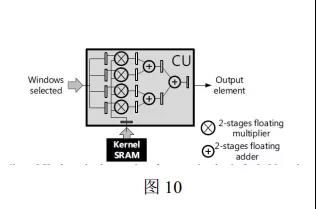
3. PE 的计算方式以及加法树的实现
PE 的职能很明确, 即接收数据进行计算, 后面采取加法树加快速度, 其实现方式示意图如下
1. Yolo 模拟结果截图如下:

紫色部分就是代表某一层, 采取资源复用的方式, 使得不同的层可以在一块资源上实现。
2. Block Design 内部逻辑如下:
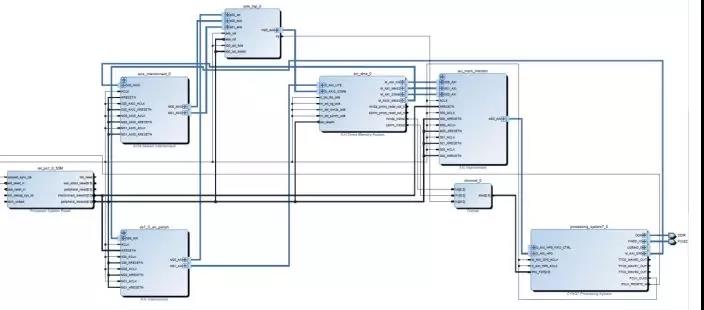
3. 连接外设后的总体架构如下:

erilog 版本的源代码写了大概 8000 行,鉴于纯 Verilog 的方案开发时间很长, 面对新的神经网络模型需要花大量时间修改, 修改难度大, debug 周期长, 与主机、 传感器的驱动复杂。 因此, 我们采用了高层次综合(HLS) 的方式进行第二版的开发。
未完待续……
更多项目内容
敬请期待下期


