本文为凌美芯团队联合上海交通大学进行的“基于 YOLO 深度神经网络的视频物体检测与识别 FPGA 加速项目”总结,我们将分3期为您展示整个项目,本期为终结篇。

作者:
Leech、董浩、江子山
上海交通大学计算机科学与工程系
刘剑、邓秋平
凌美芯(北京)科技有限责任公司
目前我们使用 Xilinx 的 HLS 进行开发, 针对的是 yolo-tiny 的最新版本, 其网络拓扑结构如下:
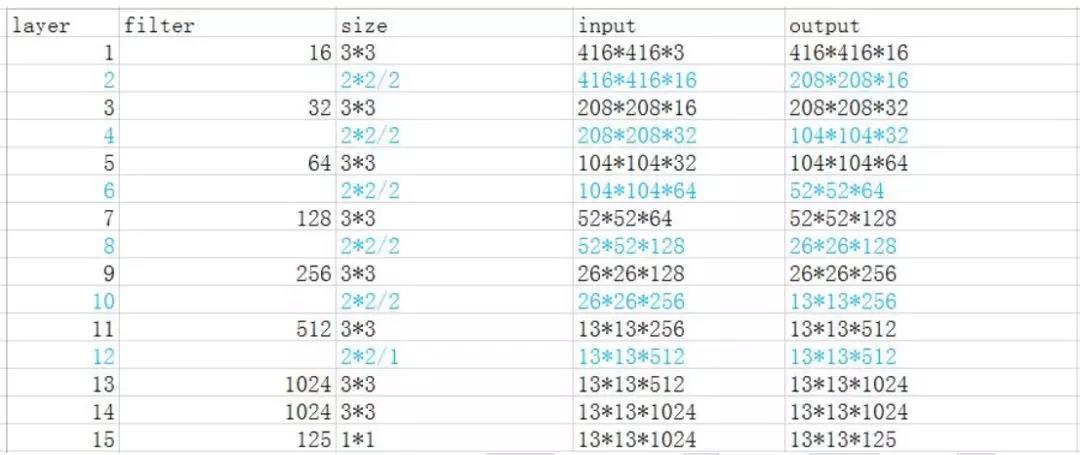
蓝色的都是池化层(Max Pooling), 其余黑色的全部都是卷积层, 没有了全连接层, 但是每个卷积层(除了最后一层卷积层) 都加了 Batch Normalization 操作, 这是其与老版本的最大区别。
我们目前的开发工具是 Vivado HLS 和 SDSoC, Vivado HLS 主要是做一些验证工作, 而SDSoC 则是主要的开发工具, 负责将我们的 C++代码转换成 RTL 代码, 并自动生成好驱动等。
1. 设计要点
参数压缩: 硬件加速模块的一个难点在于参数传输, 很多时候这个可能会成为系统的性能瓶颈。 CNN 的参数动辄几十上百兆, 一般的 FPGA 内部 BRAM 是远远放不下的, 所以必须把参数放在外部的 DRAM 中。 这也就意味着, 每处理一次前向推断, 就需要将所有的参数从外部 DRAM 传递进内部的 BRAM 中至少一次。 为什么说至少一次, 因为很多时候, 相同的参数需要被传递多次, 而且对于不同的层, 重复传递的次数还不一样。 我们当前版本的实现就属于上面这种情况。 针对我们的 yolo-tiny, 原始的参数类型是单精度浮点型, 占用空间大小为 60MB 多, 如果采取原始类型进行计算, 不仅硬件综合使用的资源量增大, 而且其参数传输带宽要求很高, 传输时间会成为系统性能的瓶颈。 我们用开源的 Ristretto 工具将浮点参数转换成了定点数, 该工具其基于 Caffe 框架, 可以获得在保持 CNN 前向推断正确率基本不变的情况下参数定点数的最佳位数, 包括整数位和小数位。 我们目前得到的是 16位, 整数位 7 位, 小数位 9 位, 运行结果和使用浮点数基本一样, CNN 推断的正确率没有损失。 若采取了量化压缩技术, 能进一步将其压缩成 8 比特, 但访存数据必须依靠索引。 该方法主要是参考韩松的神经网络参数压缩文章, 通过先对参数进行聚类, 然后每个参数就变成聚类的值的索引。 这里相比较于之前那种直接浮点转定点, 压缩率更高; 但是其由于保存的是索引, 对于每个参数都多了一个读取 BRAM 的过程。 在我们设计中, 直接浮点转定点使得参数数目减少了一半, 而量化压缩则使得参数减到了最原先的四分之一左右。
突发读取:参数传输的另一个问题其实是一次传输的数据量大小。 由于我们这里参数是随机访问的, 所以使用了 AXI Data Mover。 而在传输参数时, 如果一次只传输一个数据,那么对于一个并行度高的设计来说, 一次操作可能就需要好多次数据传输, 这就严重影响了效率。 所以, 在参数已经被转换成定点数的基础上, 我们又对参数做了封装打包, 使得多个参数被封装在了一个传输类型数据内部, 这样一次传输就可以传输多个参数, 大大减少了传输开销。 这里, 我们的并行度设计成同时执行 32 个 PE, 每个 PE 处理的对应点的深度为 32,所以每个 PE 一次计算需要的参数量其实是 32 个。 而在我们的设计中, 权重参数也被封装成 16*32 位的变量, 也就是保存了 32 个 16 比特的参数。 而对于我们 8bit 版本, 并行度又提高了一倍, 变成了 64*32, 封装力度更大, 但是原理还是一样的。
中间结果缓存:还有一个问题其实是中间结果的写回问题。 由于我们的设计采取的是资源复用的方式, 所以得在一层结果全部计算完后才可以计算下一层, 而当前层的结果保存在哪就成了问题。 如果一股脑将其全部写回到外部 DRAM, 然后计算下一层的时候再读取进来, 则增加了传输带宽压力, 造成性能损失。 考虑到有些神经网络层的中间结果很大, 内部BRAM 保存不下, 此时将结果写回到外部 DRAM, 而对于结果比较小的层, 内部 BRAM 足够大, 此时结果不写回到外部 DRAM, 直接放置在内部 BRAM 中, 节省带宽的同时也减少了计算数据准备时间, 因为数据可以直接从内部读取, 更快!
自由设定并行度:目前版本中, 我们针对 16 比特的并行度设定是 32*32,32*32, 即 32个 PE, 每个 PE 同时处理的 input feature map 是 32, 当然每个 PE 一个 clock 处理的只是每个 input feature map 的一个元素, 所以每个 clock 的计算量为 32*32 = 1024。针对 8 比特版本,并行度设定是 64*32, 其他不变, 就是同时可以处理 64 个 PE 了。 当然, 并行度是可以随着硬件资源的情况手动改变的, 而对于每个改变, 其输入参数也需要做一些相应修改, 我们提供有参数生成函数, 可以按照不同的并行度设计生成不同的参数。
2. 整体框架
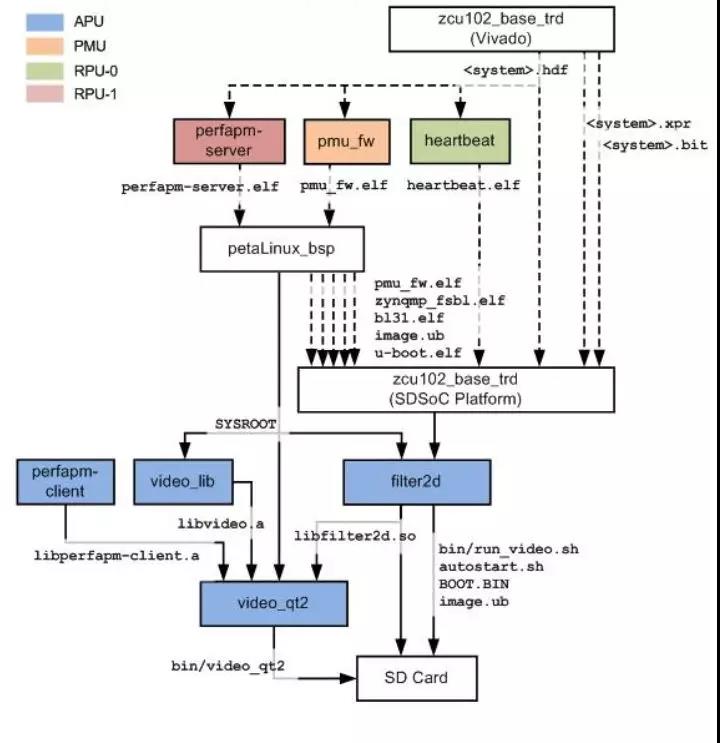
本项目主要基于 Xilinx 官方提供的 Zynq UltraScale MPSoC Base TRD 2016.4 参考设计开发, 该参考设计充分利用了 ZCU102 开发板上的 APU(运行对称多处理器 Linux 系统)、 RPU( 逻辑程序以及 FreeRTOS 实时操作系统) 以及可 PL( 用于视频处理加速) 等资源实现了一个嵌入式视频处理应用, 能够实现超高清视频的实时采集、 处理以及显示。 在本项目中,我们将其中用于实时图像处理的程序 filter2d 替换成用于程序 yolo, 从而形成本项目的基本框架。
项目框架流程如下:
1) 在参考设计中, 视频来源有三种: 软件实现的虚拟视频设备(vivid)、 USB 网络摄
像头以及在 PL 中实现的测试图发生器( TPG), 而在本项目中, 我们采用了参考设计推荐使用的罗技 C920 作为网络摄像机来采集视频数据。 这款网络摄像机在参考设计中能够实现 YUYV 格式下 5fps 的 1080p 视频采集以及 10fps 的 720p 视频采集。 网络摄像机通过 USB 接口连接到开发板上, 在 Linux 系统下, 网络摄像机被抽象成设备文件/dev/video*。

2) 视频采集。 在参考设计中, 视频的采集依赖于 V4L2 框架(Video For Linux Two),这个框架是内核提供给应用程序访问音、 视频驱动的统一接口, 可以用于在视频设备节点(/dev/video*) 上采集到视频帧, 并提供相关操作函数(例如开始/停止视频流、 设置像素格式等)。 由于罗技 C920 是 UVC 设备, 因此使用 V4L2 框架可以免驱动地获取摄像机拍摄的视频帧, 像素格式为 YUYV。
3) 视频显示。 在参考设计中, 视频显示采用了 DRM 框架(Direct Render Manager),这个框架用于配置显示数据流水线然后将视频缓冲发送到显示控制器( 此处使用Display Port 连接显示屏显示视频), 像素格式为 YUYV。
4) 视频处理。 在参考设计中, 视频处理程序 filter2d 用于实时对视频进行 2D 的图像处理, 而在本项目中, 我们替换成了我们自己写的 yolo 程序, 能够对视频进行实时监测。 由于 yolo 程序要求视频帧的像素格式为 RGB, 因此在本模块的输出和输入都需要进行 YUYV 和 RGB 之间的转换。
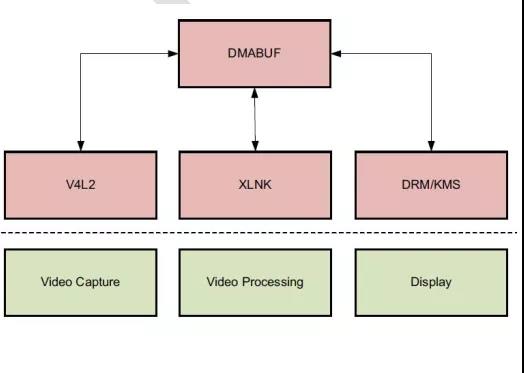
5) 视频缓冲管理。 在参考设计中, 程序采用 DMABUF 框架在显示设备、 视频采集设
备以及视频处理模块之间共享缓冲。 具体示意图如下所示:
3. YOLO 加速模块剖析
Yolo 中对于 pixel 和 weight 采取的数据格式都是 16bit 定点数, weight 的定点化采取Restritto 方案, 同时有一个特定的转换函数将其转换成加速函数需要的组织形式, 这里是将32 个 weight 压成一个大数据, 然后进行传输。
下面从源代码的角度去介绍一下加速模块。
1) Yolo 加速模块入口

其中数据类型定义如下:

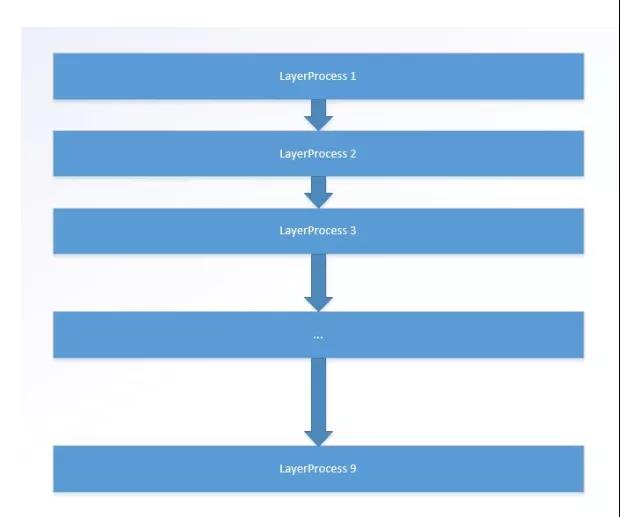
LayerProcess 就是每一层的具体处理函数, 目前的 yolo-tiny 版本共有 9 层卷积层以及一层 region layer, 由于 region layer 更适合 CPU 执行, 所以 FPGA 加速就只实现了 9 层卷积层,也就是说 Yolo 函数内共有 9 个 layerProcess 函数。
2) layerProcess 函数
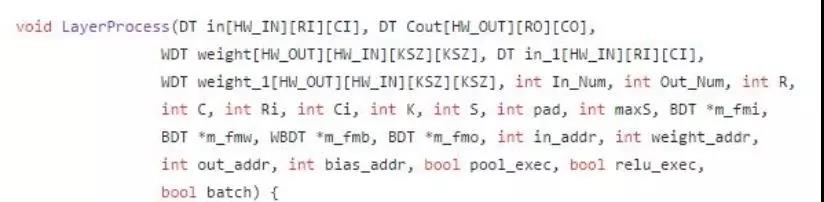
其内部流程如下:

由于每一层的 bias 相对来说比较小, 所以一开始就将全部的 bias 加载进 BRAM 里面,然后卷积处理循环处理根据之前的配置, 每次处理 HW_OUT 个 kernel, 每个 kernel 同时处理 HW_IN 个 input feature map。 同时, 内部采取了 pingpong 方式使得数据加载和数据处理能够同时执行。 当卷积层处理 in 和 weight 的时候, 加载模块同时将下一次需要的数据加载到 in_1 和 weight_1 内, pingpong 操作减少了数据等待时间, 极大的提高了执行速度。
3) 数据加载模块
这里的数据主要指 Weight 和 Pixel。 为了提高传输效率, 传输进来的数据其实都是 BDT和 WBDT 类型, 根据上面的类型定义可知, 这些类型都是将许多数据组合在一起形成的“大数据” 类型, 每个数据包含了多个元素, 其中, 为了保持并行性等要求, 有一部分数据还是用 0 填充的数据, 而这些都是转换函数在转换的时候完成的。 该模块主要是将每个元素提取出来, 然后保存在 pixel 和 weight 数组中, 也就是上面的 in(in_1) 和 weight(weight_1)。
4) 卷积层
这里是加速最重要的模块。 按照配置, 这里一次处理 32 个 kernel, 然后每个 kernel 一次处理 32 个 input feature map。 大致结构如下:
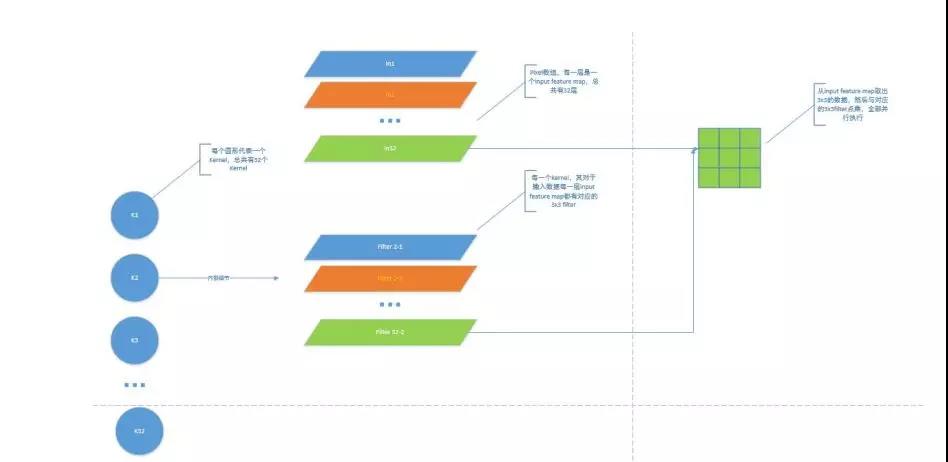
这里只画出了一个 kernel 对应某一个 input feature map 进行的计算, 实际上 32 个 kernel同时对 32 个 input feature map 进行计算, 也就是同时有 32x32=1024 个 DSP 在进行计算。 如果 DSP 更多, 完全可以增大并行度, 同时进行 64x32=2048 个乘加操作, 处理速度会更快,但是加速比还打不到目前的 2 倍, 因为前面很多层并没有 64 个 kernel 或者 input feature map没有 64, 这也是为什么在包装数据的时候会填充很多 0 的原因。
5) Pooling 层
这里采取的 pooling 都是 max pooling, maxS 表示 max pooling 的 stride, 其值为 2, 主要过程如下:
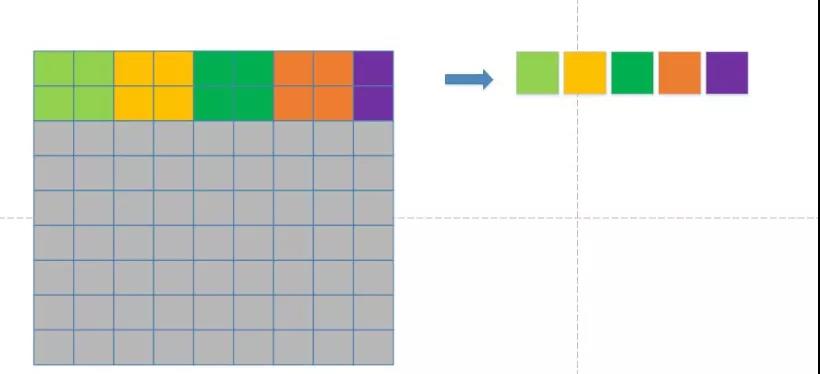
对于每一个 2x2 的区域, 取出其中最大的一个值, 但是我们很多层的 output feature map是 13x13, 也就是总会有一个类似上面紫色的部分, 这部分的 pooling 只需要取这两个之中最大的一个即可。 在实现的时候, 补充两个表示范围内最小的数, 从而与前面保持一致。 当然, pooling 里面对于不同的 output feature map, 操作是并行进行的。
6) 激活层
这里的激活层相比于之前, 加入了 Batch Normalization 操作。 在前面加载 bias 的时候,其实也加载了 BatchNorm 需要的 variance,mean 以及 scale 数据。 除了最后一层, 每一层都需要 BatchNorm 操作。

可以看出, 这里也全部展开了, 里面的操作都是并行执行的。
7) 数据输出模块
数据输出模块和数据加载模块做的是完全相反的事情, 其将需要传输的数据打包好, 将
HW_OUT 个元素组成一个大元素, 然后传输出去, 都是为了提高传输效率。
对于 HLS 的开发, 表面上是简化了开发难度, 但是如果对于硬件不是很了解, 使用 HLS是无法发挥硬件的巨大优势的, 如果想使用高级语言开发出很好的硬件程序, 你必须对于自己写的每一部分的代码, 都能清楚的指导这部分代码在硬件中会综合成什么样, 这样, 你才能合理的设计代码, 使得综合出来的硬件逻辑满足预期的目标。
上面主要从架构和设计的角度介绍了我们之前和现在两个不同的工作, 前面是使用 RTL级语言完成, 后面使用高级语言综合完成。不管采取哪一种方式, 想要设计出好的代码,都得对硬件有足够的了解。我们前期的工作为后面的工作奠定了基础, 通过手动实现一版完整的 Verilog 版本的 Yolo, 我们对于 FPGA 硬件的结构和特性以及硬件的设计思路有了很深厚的认识, 这为我们后面使用 HLS 设计代码带来了极大好处。我们探索过很多种设计方案,架构图也设计了很多很多, 每种基本上都测试过, 最终选择的是我们觉得性能最好的。
- 全文完结 -
更多项目内容
敬请期待

LYNMAX凌美芯
微信号:LYNMAXTECH

